# JS基础面试题
# ['1', '2', '10'].map(parseInt)
TIP
输出结果[1,NaN,2] parseInt(str,n)
把第一个参数看作是一个数的n进制的表示,而返回的数值则是十进制;
如parseInt('123',5);将'123'当做5进制的数,返回十进制 1 * 5^2 + 2 * 5^1 + 3 * 5^0 = 38
如果第一个参数中不存在n进制的表示数字,则返回能解析的部分,parseInt('15',2) = 1
# setTimeout、Promise、async/await 的区别
# setTimeout
setTimeout的回调函数是放到宏任务队列里;(等到执行栈清空后执行)
# Promise
Promise本身执行时是同步的,then产生的回调函数是放到微任务队列里
# async/await
async函数表示函数里可能会有异步的方法,await后面跟一个表达式,async方法执行时,遇到await会立即执行await后面的表达式,然后把表达式后面的代码放到微任务队列里,让出执行栈让同步代码先执行
# JS异步解决方案的发展历程以及优缺点
# 回调函数
TIP
优点
- 1、解决了同步问题
缺点
- 缺乏顺序性:回调地域导致的调试困难
- 嵌套函数耦合性高;
- 嵌套过多很难处理错误
- 不能
return
# Promise
TIP
优点
- 1、解决了回调地狱的问题
缺点
- 一旦开始就无法取消
- 不知道内部进行到哪个阶段
- 错误需要通过回调函数来捕获
# Async/await
TIP
终极的异步解决方案
优点
- 代码清晰,处理了地域回调的问题
缺点
await将异步变同步,多个异步操作如果没有依赖关系,使用await会导致性能下降
# ES5/ES6 的继承除了写法以外还有什么区别
TIP
继承的机制不同
ES5:先生成子类的实例,再调用父类的构造函数修饰子类的实例,由于父类的内置属性无法获取,导致无法继承原生的构造函数。(比如,Array构造函数有一个内部属性[[DefineOwnProperty]],用来定义新属性时,更新length属性,这个内部属性无法在子类获取,导致子类的length属性行为不正常。)ES6:先生成父类的实例,再调用子类的构造函数修饰生成的实例。由于这个差异,使得ES6继承可以继承内置对象。
# 事件循环在浏览器和 node 中的区别
TIP
浏览器中:
- 执行所有
同步js代码→ 执行所有微任务→渲染页面→执行一个宏任务→执行宏任务产生的微任务→渲染页面→执行下一个宏任务→执行宏任务产生的微任务→循环……
node中:
timers阶段:这个阶段执行timer(setTimeout、setInterval)的回调I/O callbacks阶段:处理一些上一轮循环中的少数未执行的I/O回调idle, prepare阶段:仅node内部使用poll阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里check阶段:执行setImmediate()的回调close callbacks阶段:执行socket的close事件回调
上面六个阶段都不包括 process.nextTick()
- node10以前
- 执行一个阶段的所有任务→执行完
nextTick队列里的任务→执行所有的微任务
- 执行一个阶段的所有任务→执行完
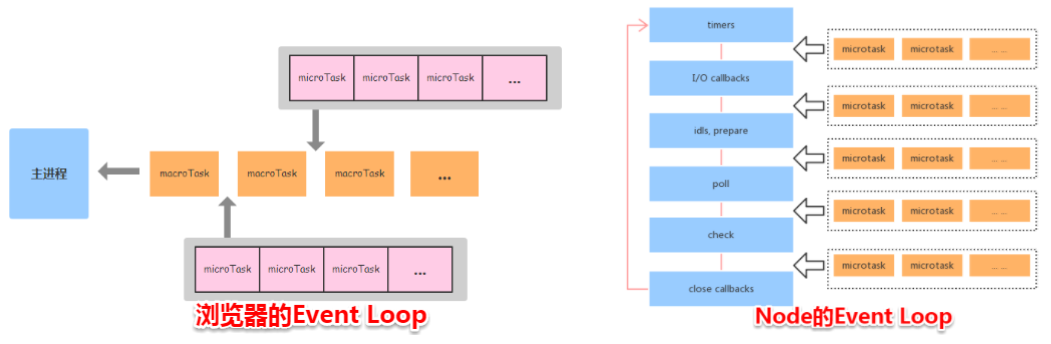
- node11以后
- 和浏览器做了统一
# 模块化进程
IIFE:最开始采用自执行函数形成私有作用域来编写模块化,避免变量冲突
AMD:采用requireJs编写模块化,特点:必须提前进行声明
CMD:采用Sea.js来编写模块化,特点:可以动态导入模块
CommonJS:nodeJS中自带的模块化(require的导入方式)
UMD:兼容AMD,CommonJS模块化语法;
ES6 Modules:ES6引入的模块化,支持import导入另一个JS
# DOCTYPE 的作用
告诉浏览器的解析器,用什么文档标准来解析文档。如果
DOCTYPE不存在或者格式不正确,文档将以兼容模式呈现。
# 兼容模式和标准模式的区别
标准模式的渲染方式和
JS引擎的解析方式都以该浏览器最新的标准去运行。在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为以防站点无法工作。
# 为什么HTML5不需要DTD?
DTD的作用是用来定义文档中的规则。因为HTML5以前都是基于SGML的,所以需要通过制定DTD来制定文档的规则。而HTML5不是基于SGML的,所以不需要DTD;
# 前端性能优化
# 页面内容方面
页面内容
- 1、使用
CSS雪碧图、图片小于1M时,使用base64来减少HTTP请求,避免请求过多。 - 2、通过设置缓存策略,对常用不变的资源进行缓存
- 3、非必要资源采用延迟加载的方式来请求。
- 4、使用代码移除(
Tree-shaking),作用域提升(Scope hoisting)和代码分割(Code-splitting)来减少有效负载;
# 服务器方面
服务器
- 1、使用
CDN服务,来提高用户对于资源的请求速度 - 2、服务器开启
Gzip、Deflate等方式对于传输的资源进行压缩,减小文件体积 - 3、尽可能减少
cookie的大小,并且通过将静态资源分配到非主域名下,来避免请求静态资源时携带不必要的Cookie(也叫cookie隔离)
# 精度丢失问题
0.1 + 0.2 === 0.3
为什么0.1 + 0.2 === 0.3 在JS中运算结果为false?
JS使用Number类型表示数字(整数和浮点数),遵循 IEEE754 标准,适用64位固定长度来表示,也就是标准的double双精度浮点数,
- 1 :符号位,0表示正数,1表示负数
- 11 :指数位(e)
- 52 : 尾数,小数点后面的部分(即有效数字) 这样的存储结构的好处在于可以统一的处理整数和小数,节省存储空间
在运算时, 十进制的 0.1 和 0.2 会被转换成二进制的双精度浮点数,转换后会无限循环。由于IEEE754 的尾数限制最多52位,需要将超出的部分截掉,截取采用0舍1入的原则。
0.00011001100110011001100110011001100110011001100110011010
+0.00110011001100110011001100110011001100110011001100110100
------------------------------------------------------------
=0.01001100110011001100110011001100110011001100110011001110
这样在进制的转换中,精度已经丢失,所以相加之后会出现偏差,这就是精度丢失的根本原因。再转换为二进制也就不为0.3了
解决方法:
- 1、ES6在
Number对象上新增了一个极小的常量Number.EPSILON,可以用此常量为浮点数设置一个误差范围,只要误差小于Number.EPSILON,我们就可以认为结果是可靠的 - 2、将小数放大为整数(乘10的N次方),然后进行算术运算,最后再缩小为小数(除法)
- 3、使用第三方库如math.js、big.js
# script标签阻塞页面加载
script阻塞
普通的script脚本(不带defer、async属性),会阻塞页面的解析,当解析到普通的script外部脚本时,会等待script脚本下载并执行完毕之后,才会继续解析HTML。但是可以加上defer 或 async属性,这样脚本就都变成了异步下载,不会阻塞页面的解析。只是根据属性不同,执行的时机不同。
async:异步下载完成之后就立即执行(根据下载完成事件执行,所以顺序会有问题)。执行时会阻塞页面的解析。
defer:延迟到页面解析完成之后,DOMContentLoaded事件之前按照顺序执行完成(实际可能不按顺序,而且不在DOMContentLoaded事件之前执行完)。
async
(高程4解析)
async(HTML5):异步执行脚本(只对外部脚本文件有效)
添加了defer属性的script外部脚本,表示立刻开始下载脚本,能够异步的加载脚本,而且不会阻塞页面的加载。但是一旦下载完成就会立刻执行,执行时会阻塞页面的加载,所以异步脚本不应该在加载期间修改DOM。而且很可能不会按照原本的顺序执行。
异步脚本保证会在页面load时间之前执行,但可能会在DOMContentLoaded(DOM结构加载完成)事件之前或之后执行。
情况一:HTML未解析完,async脚本已经加载完成,HTML停止解析,去执行脚本,脚本执行完毕后,HTML继续解析。HTML解析完成后触发DOMContentLoaded事件。
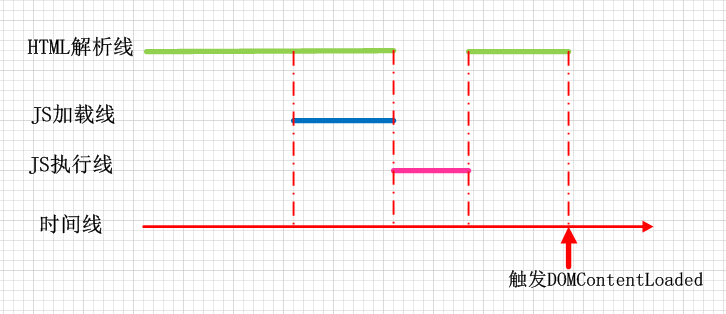
情况二:HTML解析完成后,async脚本才加载完成,然后执行脚本。在HTML解析完成后就触发了DOMContentLoaded事件。
defer
defer(HTML4.01):推迟执行脚本(只对外部脚本文件有效)
遇到带有defer属性的script外部脚本,会立即下载,但是只会在浏览器解析到结束的</html>标签后才会按照顺序执行,并且都会在 DOMContentLoaded事件之前执行(实际不一定按照顺序执行或在DOMContentLoaded(DOM结构加载完成)事件之前执行,因此最好只包含一个这样的脚本)
这个属性表示脚本在执行的时候不会改变页面的结构。也就是说脚本会被延迟到文档完全被解析和显示后再执行。设置了defer属性,相当于告诉浏览器该脚本立即下载,但是延迟执行。
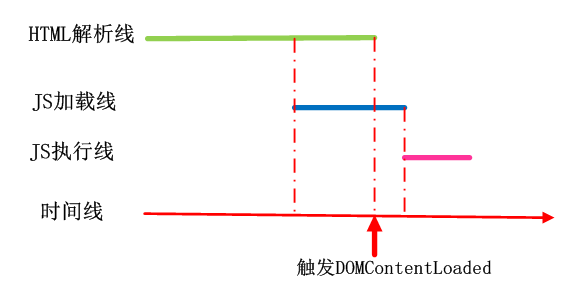
情况一:HTML未解析完,defer脚本已经加载完成,等待HTML解析完成后,去执行脚本,脚本执行完毕后触发DOMContentLoaded事件。
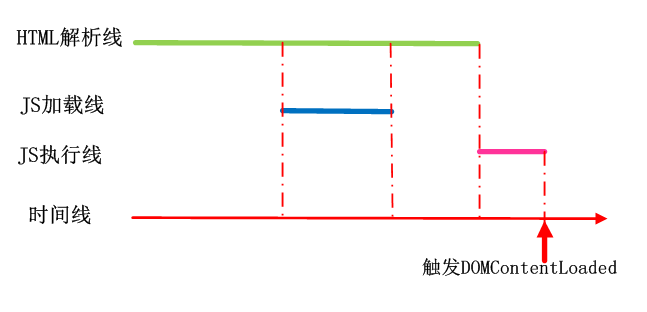
情况二:HTML解析完成后,defer脚本才加载完成,然后执行脚本,脚本执行完毕后触发DOMContentLoaded事件。
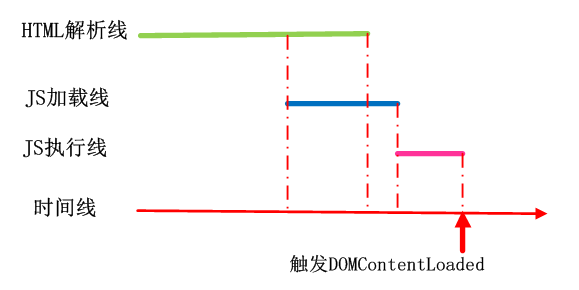
共同点:
- 1、下载脚本时不会阻塞页面的加载(执行时会)
- 2、只对外部脚本文件有效
- 3、都在
load事件之前执行完毕
# css阻塞页面加载么?
TIP
css为什么一般都要放在head中?
css的下载是异步的,不会阻塞HTML的解析(DOM树的构建)。但是会阻塞页面的渲染。
把CSS放在head中是为了防止加载出来的页面没有样式,看起来丑,然后样式加载完成后闪一下。好处在于加载出来的页面直接就是带有样式的,但是在页面未显示之前页面是白屏状态。
页面展示流程:
- 1、渲染进程解析
HTML,计算DOM结构,生成DOM Tree。 - 2、解析
HTML时,遇到CSS,会异步下载并解析,生成Style Rules,不会阻塞HTML的解析。 - 3、解析
HTML时,遇到script(不带defer、async属性),会停止HTML的解析,开始下载并执行脚本,直到执行完成之后,继续解析HTML。 - 4、合并
DOM Ttree和Style rules生成render Tree(渲染树) - 5、根据
render树(重绘和回流Layout/reflow)开始进行元素布局,负责各元素尺寸、位置的计算 - 6、绘制
render树(paint),绘制页面像素信息 - 7、浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上
# ES6解构赋值、默认值
function move1({ x = 0, y = 0 } = {}) {
return [x, y];
}
console.log(move1({})) // [0,0]
console.log(move1()) // [0,0]
TIP
为什么两道题都是[0,0]?
如果没有传值,则给的默认值是空对象{},然后再对值进行解构,那么传参数{}和不传应该是一样的结果,因为默认值是{}。然后解构,空对象中没有x,y,则取x,y的默认值0,0,所以结果是[0,0]。
# 滚动条滚动会导致回流么?
TIP
滚动条滚动时对于非Fixed定位的元素,是不会回流的。但是对于Fixed定位的元素,在滚动条滚动的时候是会一直回流的。
# 服务端渲染原理
TIP
服务端渲染意思是首屏页面中HTML中的内容是在后端(node)插入到HTML当中的,然后返回给前端直接进行渲染的。
用webpack打包出两份代码,一份服务端的,一份客户端可以直接访问的。其中,服务端打包出的HTML的body元素中只有一个占位符和需要引入客户端js一个script标签,以便在node服务器渲染出需要展示的内容之后,插入到body元素当中。然后返回给客户端,客户端就可以直接展示内容了。
打包服务端js时,因为需要给node端使用,所以需要改为node端导入导出方式,这样才能在node端导入。
output:{
libraryTarget: 'commonjs2' // 打包出的js会在外部包上 module.exports导出
}
但是只有要展示的内容,所有的事件以及JS功能都是不生效的。所以,我们需要把打包出来的客户端代码中的js部分,采用ejs模板的方式注入到后端渲染的HTML中,这样就带有JS功能了(在打包的时候就直接配置即可)
// webpacl.server.js
plugins:[
new HtmlWebpackPlugin({
template: xxxx,
filename:'server.html',
minify:false,
client: '/client.bundle.js' // 需要注入js文件的名
})
]
<body>
<!-- 占位符 -->
<!-- 采用ejs模板方式,将客户端打包出的js 注入到HTML中 -->
<script src="<%=htmlWebpackPlugin.options.client%>"></script>
</body>
这样就实现了服务端渲染,而且还带有JS功能的HTML了。
# 移动端实现1px
TIP
1px 的边框。在高清屏下,移动端的1px会很粗
为什么移动端会有1px的问题?
一般多倍的屏幕设计图设计了1px的边框,在手机上缩小呈现时,由于css最低只支持显示1px大小,导致边框太粗的效果,实际是一种视觉差,并非1px真的变粗了。
- 1、使用伪元素 +
border+transform:scale.div::after { content: ''; width: 200%; height: 200%; position: absolute; top: 0; left: 0; border: 1px solid #bfbfbf; border-radius: 4px; -webkit-transform: scale(0.5,0.5); transform: scale(0.5,0.5); -webkit-transform-origin: top left; } - 2、使用
box-shadow模拟边框,利用css对阴影处理的方式实现0.5px的效果 缺点:阴影导致的颜色变浅,而且仔细看谁都看得出这是阴影而不是边框。。。.box-shadow-1px { box-shadow: 0 -1px 1px -1px #e5e5e5, //上边线 1px 0 1px -1px #e5e5e5, //右边线 0 1px 1px -1px #e5e5e5, //下边线 -1px 0 1px -1px #e5e5e5; //左边线 } - 3、采用
background-image && boder-image解决 缺点:换个颜色还得换图,而且图片处理圆角会出现模糊的问题.background-image-1px { background: url(...) no-repeat left bottom; -webkit-background-size: 100% 1px; background-size: 100% 1px; } .border-bottom-1px { border-width: 0 0 1px 0; -webkit-border-image: url(...) 0 0 2 0 stretch; border-image: url(...) 0 0 2 0 stretch; } - 4、采用
viewport + rem页面初始化时,引入下面的标签。接下来就是通过<meta name="viewport" id="WebViewport" content="initial-scale=1, maximum-scale=1, minimum-scale=1, user-scalable=no">js动态的修改缩放比,以及实现rem根元素字体大小的设置var viewport = document.querySelector("meta[name=viewport]") if (window.devicePixelRatio == 1) { viewport.setAttribute('content', 'width=device-width, initial-scale=1, maximum-scale=1, minimum-scale=1, user-scalable=no') } if (window.devicePixelRatio == 2) { viewport.setAttribute('content', 'width=device-width, initial-scale=0.5, maximum-scale=0.5, minimum-scale=0.5, user-scalable=no') } if (window.devicePixelRatio == 3) { viewport.setAttribute('content', 'width=device-width, initial-scale=0.333333333, maximum-scale=0.333333333, minimum-scale=0.333333333, user-scalable=no') } var docEl = document.documentElement; var fontsize = 10 * (docEl.clientWidth / 320) + 'px'; docEl.style.fontSize = fontsize;
# vue中运行时和完整版的区别
TIP
vue的完整版是带有编译器的,运行时的版本是不带编译器的,相比完整版体积减小了30%。如果没有编译器,你在vue中写的template:'<div> </div>'就无法转化为原始的html。与其在客户端编译,为什么不在打包的时候就编译好再发给用户呢?这样就节省了引入包的体积。
运行时版本是不需要编译器的,他是通过在打包的时候就使用vue-loader将vue文件转换为h函数所需要的参数
# XSS攻击
TIP
XSS 攻击指的是跨站脚本攻击,是一种代码注入攻击。攻击者通过在网站注入恶意脚本,使之在用户的浏览器上运行,从而盗取用户的信息如 cookie 等。
XSS 的本质是因为网站没有对恶意代码进行过滤,与正常的代码混合在一起了,浏览器没有办法分辨哪些脚本是可信的,从而导致了恶意代码的执行。
XSS 一般分为存储型、反射型和 DOM 型。
存储型指的是恶意代码提交到了网站的数据库中,当用户请求数据的时候,服务器将其拼接为 HTML 后返回给了用户,从而导致了恶意代码的执行。
反射型指的是攻击者构建了特殊的 URL,当服务器接收到请求后,从 URL 中获取数据,拼接到 HTML 后返回,从而导致了恶意代码的执行。
DOM 型指的是攻击者构建了特殊的 URL,用户打开网站后,js 脚本从 URL 中获取数据,从而导致了恶意代码的执行。
XSS 攻击的预防可以从两个方面入手,一个是恶意代码提交的时候,一个是浏览器执行恶意代码的时候。
对于第一个方面,如果我们对存入数据库的数据都进行的转义处理,但是一个数据可能在多个地方使用,有的地方可能不需要转义,由于我们没有办法判断数据最后的使用场景,所以直接在输入端进行恶意代码的处理,其实是不太可靠的。
因此我们可以从浏览器的执行来进行预防,一种是使用纯前端的方式,不用服务器端拼接后返回。另一种是对需要插入到 HTML 中的代码做好充分的转义。对于 DOM 型的攻击,主要是前端脚本的不可靠而造成的,我们对于数据获取渲染和字符串拼接的时候应该对可能出现的恶意代码情况进行判断。
还有一些方式,比如使用 CSP ,CSP 的本质是建立一个白名单,告诉浏览器哪些外部资源可以加载和执行,从而防止恶意代码的注入攻击。
还可以对一些敏感信息进行保护,比如 cookie 使用 http-only ,使得脚本无法获取。也可以使用验证码,避免脚本伪装成用户执行一些操作。